AWS
AWS
How to copy files from S3 to PostgreSQL RDS
When you have millions of entries of data to be inserted into PostgreSQL as a backup or for any reason, its often hard to iterate and insert into a table. For this scenario, PostgreSQL AWS extensions provide COPY command for S3 files to copy files from S3 to PostgreSQL RDS directly.
First we will see what’s the COPY command does. According to the official documentation
https://www.postgresql.org/docs/current/sql-copy.html
COPYmoves data between PostgreSQL tables and standard file-system files.COPY TOcopies the contents of a table to a file, whileCOPY FROMcopies data from a file to a table (appending the data to whatever is in the table already).COPY TOcan also copy the results of aSELECTquery.
Following is the COPY command syntax
COPY table_name [ ( column_name [, ...] ) ]
FROM { 'filename' | PROGRAM 'command' | STDIN }
[ [ WITH ] ( option [, ...] ) ]
[ WHERE condition ]
COPY { table_name [ ( column_name [, ...] ) ] | ( query ) }
TO { 'filename' | PROGRAM 'command' | STDOUT }
[ [ WITH ] ( option [, ...] ) ]
where option can be one of:
FORMAT format_name
FREEZE [ boolean ]
DELIMITER 'delimiter_character'
NULL 'null_string'
HEADER [ boolean ]
QUOTE 'quote_character'
ESCAPE 'escape_character'
FORCE_QUOTE { ( column_name [, ...] ) | * }
FORCE_NOT_NULL ( column_name [, ...] )
FORCE_NULL ( column_name [, ...] )
ENCODING 'encoding_name'One important point is COPY command doesn’t
To move the file to RDS, AWS has an extension of COPY command that can be installed directly to PostgreSQL. Let’s dive into the steps.
1. Install AWS S3 extension in PostgreSQL to copy files from S3 to PostgreSQL RDS
First, following are the steps that are required to write the file from S3 to the RDS
- Create a secure signed link to the file which can read the file
- COPY the file from S3 to RDS and update the table.
To run the COPY command you will first need to install the aws_s3 extension. https://github.com/chimpler/postgres-aws-s3. Login to the PostgreSQL from a secure connection and execute the following.
postgres=> CREATE EXTENSION aws_s3 CASCADE;
NOTICE: installing required extension "aws_commons"
CREATE EXTENSIONIf you have a public link you can login using following
psql --host=123456789.aws-region.rds.amazonaws.com --port=5432 --username=postgres --passwordYou can execute\dx command to verify whether the extension is installed
postgres=> \dx
List of installed extensions
Name | Version | Schema | Description
-------------+---------+------------+---------------------------------------------
aws_commons | 1.2 | public | Common data types across AWS services
aws_s3 | 1.1 | public | AWS S3 extension for importing data from S3
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(3 rows)2. Get a secure link to the S3 file
Now we can see how to get a secure link to the data file in S3. The data file should be in CSV format. You can use a custom delimiter other than , and create a file with records. Note that the records should be exactly as the rows in the table.
Example data files in CSV format
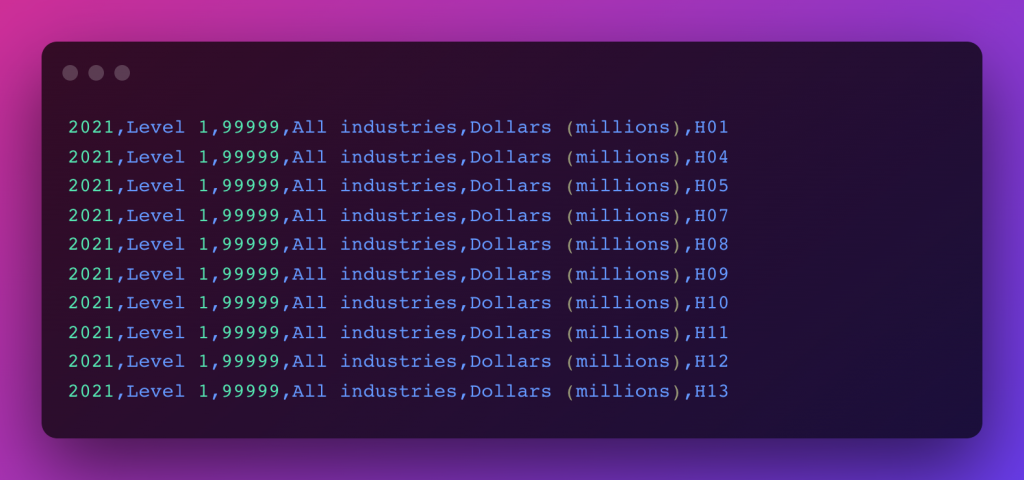
With |delimiter as the separator. Useful when you have comma-separated texts in between

You can save this file to an s3 bucket and get its path
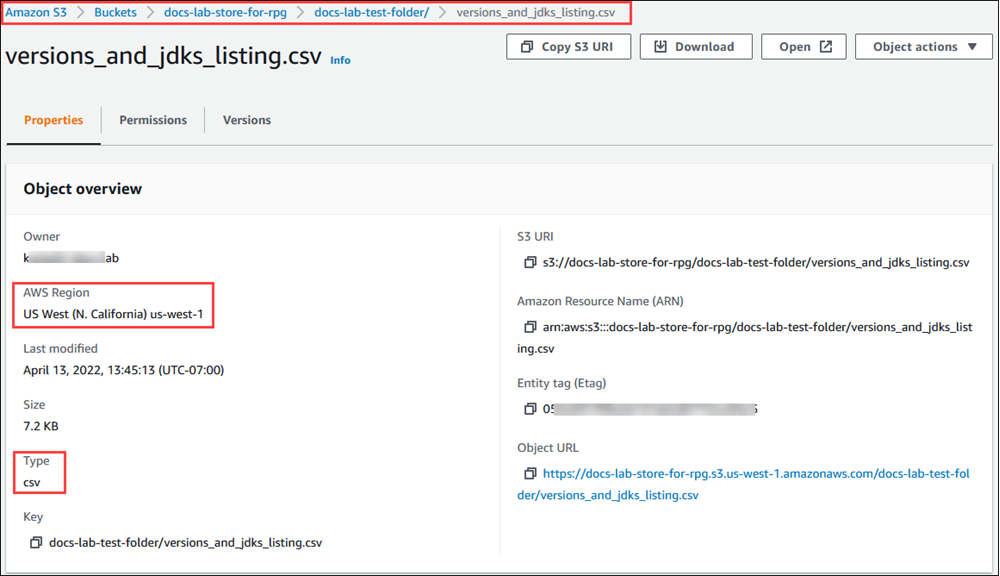
Next you have to create a secure link to this file. For that, you can use the following query.
bucket = docs-lab-store-for-rpg
filename = '/docs-lab-test-folder/version_and_jdks_listing.csv'
region = 'us-west-1'
command = """
SELECT aws_commons.create_s3_uri(
'{bucket}',
'{filename}',
'{region}'
) as uri
"""
query = command.format(bucket=bucket, filename=filename, region=region)This will create a link for the s3 file and we can use it with the aws_s3.table_import_from_s3 function
bucket = docs-lab-store-for-rpg
filename = '/docs-lab-test-folder/version_and_jdks_listing.csv'
region = 'us-west-1'
access_key = 'acccessKeyToSign'
secret_key = 'secretKeyToSign'
command = """
with s3 AS (
SELECT aws_commons.create_s3_uri(
'{bucket}',
'{filename}',
'{region}'
) as uri
)
SELECT aws_s3.table_import_from_s3(
'my_table', '', '(format csv, DELIMITER ''|'')',
(select uri from s3),
aws_commons.create_aws_credentials('{access_key}', '{secret_key}', '')
)
"""
query = command.format(bucket=bucket, filename=filename, region=region, access_key=access_key, secret_key=secret_key)Now when you execute this with psycopg or equivalent python client it will import your file to the RDS.
3. How to insert auto-generating ID
If your data has auto-generating IDs it will give an error as the copy command doesn’t know which columns to enter the data. For that, you can specify what each comma separate value represents in terms of the columns.
You can modify the command as follows
SELECT aws_s3.table_import_from_s3(
'my_table', '
Year,
Industry_aggregation_NZSIOC,
Industry_code_NZSIOC,
Industry_name_NZSIOC,
Units,
', '(format csv, DELIMITER ''|'')',
(select uri from s3),
aws_commons.create_aws_credentials('{access_key}', '{secret_key}', '')
)4. How to deal with constraints
When you are executing if you get a constraint fails the query will stop. For that, you can copy data to a temporary table and insert all data from the temporary table to the destination table by ignoring constraints.
CREATE TEMP TABLE tmp_table
(LIKE my_table INCLUDING DEFAULTS)
ON COMMIT DROP;
// copy to tmp_table
INSERT INTO my_table
SELECT *
FROM tmp_table
ON CONFLICT DO NOTHINGThat’s it. Also if you need information how to save data to CSV file using python, you can refer following.